Case Study:
Saga — Building Observability for an AI Travel Extraction System
Impact Summary
- Built an internal tool to see what our AI extraction system was actually doing (instead of guessing)
- Created a real dataset + ground truth so we could measure prompt performance properly
- Found major issues early (e.g. flights had 0% perfect extraction)
- Improved key areas like flight parsing by ~40%+ through targeted iterations
- Helped shift the team from “tweak and hope” → structured testing and iteration
- Pushed the system from a single prompt → a more reliable multi-step workflow
Context
Saga is an AI-powered product by DTravel that connects to a user’s email and photo library to automatically reconstruct travel history. It parses unstructured inputs—flight confirmations, hotel bookings, tickets, and receipts—and converts them into structured trips visualized on a map.
The underlying system relied on LLM-based prompt extraction to convert raw emails into structured travel activities.
Early on, it became clear that accuracy at this layer was existential to the product. Trips are auto-generated—there’s no manual fallback—so if parsing fails, the experience breaks completely. Users don’t debug—they churn.
Problem
Despite the sophistication of the extraction system, it functioned as a black box.
- No visibility into what data was being extracted from individual emails
- No way to systematically evaluate prompt performance
- No prompt versioning or controlled testing
- Debugging required manual database tracing (Gmail ID → extraction ID → metadata)
- Conflicting, anecdotal user feedback with no system-level signal
At the same time, the system itself was fragile:
- A single prompt handled classification + extraction
- Failures were hard to isolate (was it classification? parsing? formatting?)
- Improvements in one area often caused regressions elsewhere
This wasn’t just a tooling gap—it was a systems problem.
My Role
This was a self-initiated project.
I identified the gap while working with the extraction system and proposed a solution to the team via a detailed strategy doc and Slack proposal—covering dataset design, evaluation methodology, and system architecture.
Execution velocity
- MVP built solo in 4–5 days (including weekend/out-of-hours)
- Deployed to dev and accessible to the team within ~1 week after buy-in
- First measurable results within 2 weeks, with continuous iteration thereafter
I then:
- Defined the evaluation model (field accuracy vs record accuracy)
- Designed the workflows (dataset creation, labeling, prompt testing)
- Built the internal tool end-to-end using Next.js
- Drove alignment across product and engineering to adopt the system
This wasn’t just a UI layer—I was effectively defining how the team would reason about and improve an AI system.
Approach
The key insight was:
We weren’t blocked by model capability—we were blocked by lack of visibility.
Instead of continuing to tweak prompts blindly, I reframed the problem as building an evaluation and observability system around the model.
The goal was to create a tight feedback loop between:
- Raw input (emails)
- Expected output (ground truth)
- Model output (LLM extraction)
- Measurable evaluation
1. Creating a Training Dataset Pipeline
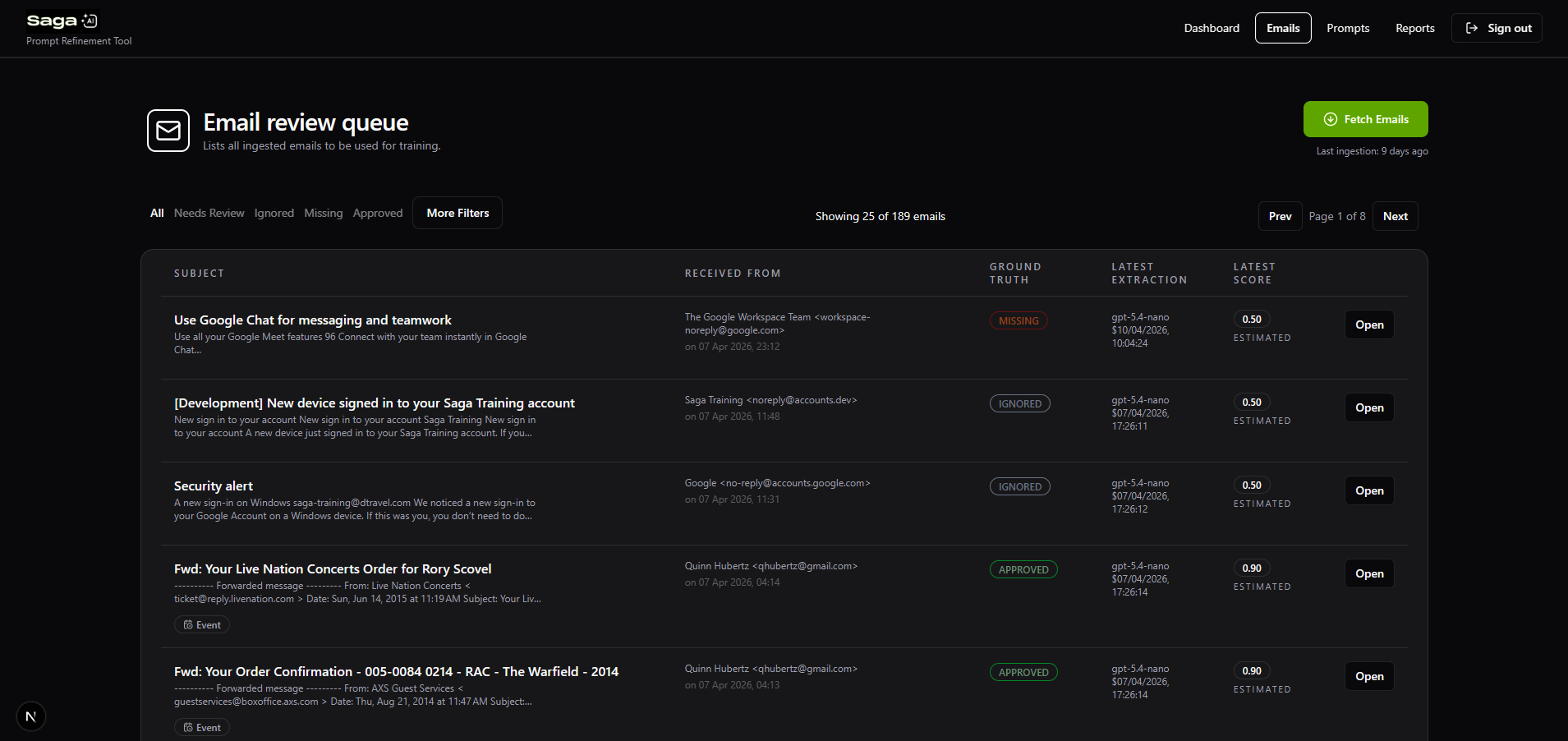
We introduced a shared inbox where team members could forward real travel emails.
This allowed us to:
- Build a centralized dataset of real-world inputs
- Continuously expand coverage across providers (Airbnb, Booking.com, airlines, etc.)
- Avoid synthetic or overly clean test data
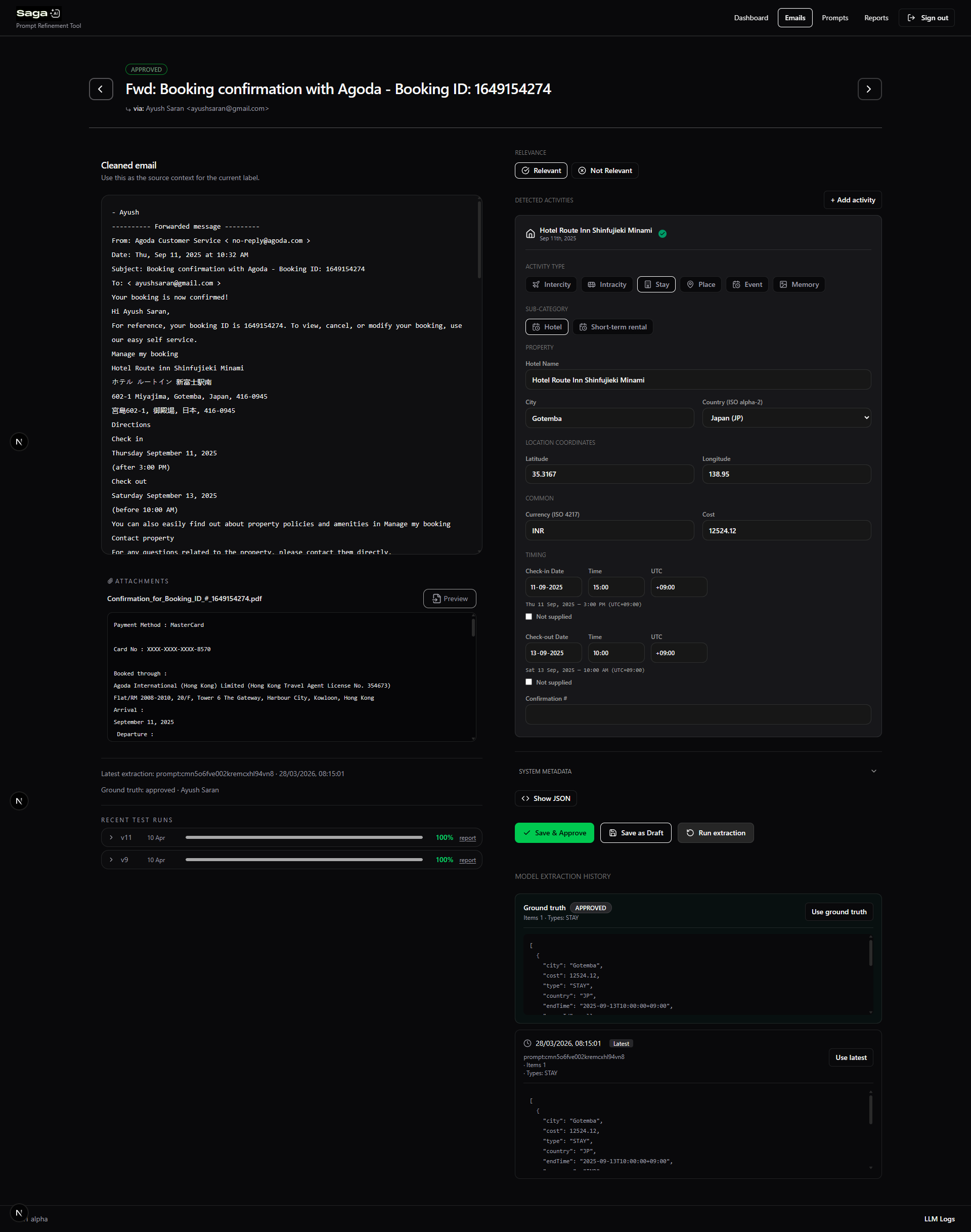
2. Ground Truth Labeling Interface
I designed a UI that allowed team members to manually label each email:
- Travel relevance (yes/no)
- Structured attributes (dates, location, provider, cost, etc.)
This produced a normalized JSON representation of truth, which became the benchmark for evaluation.
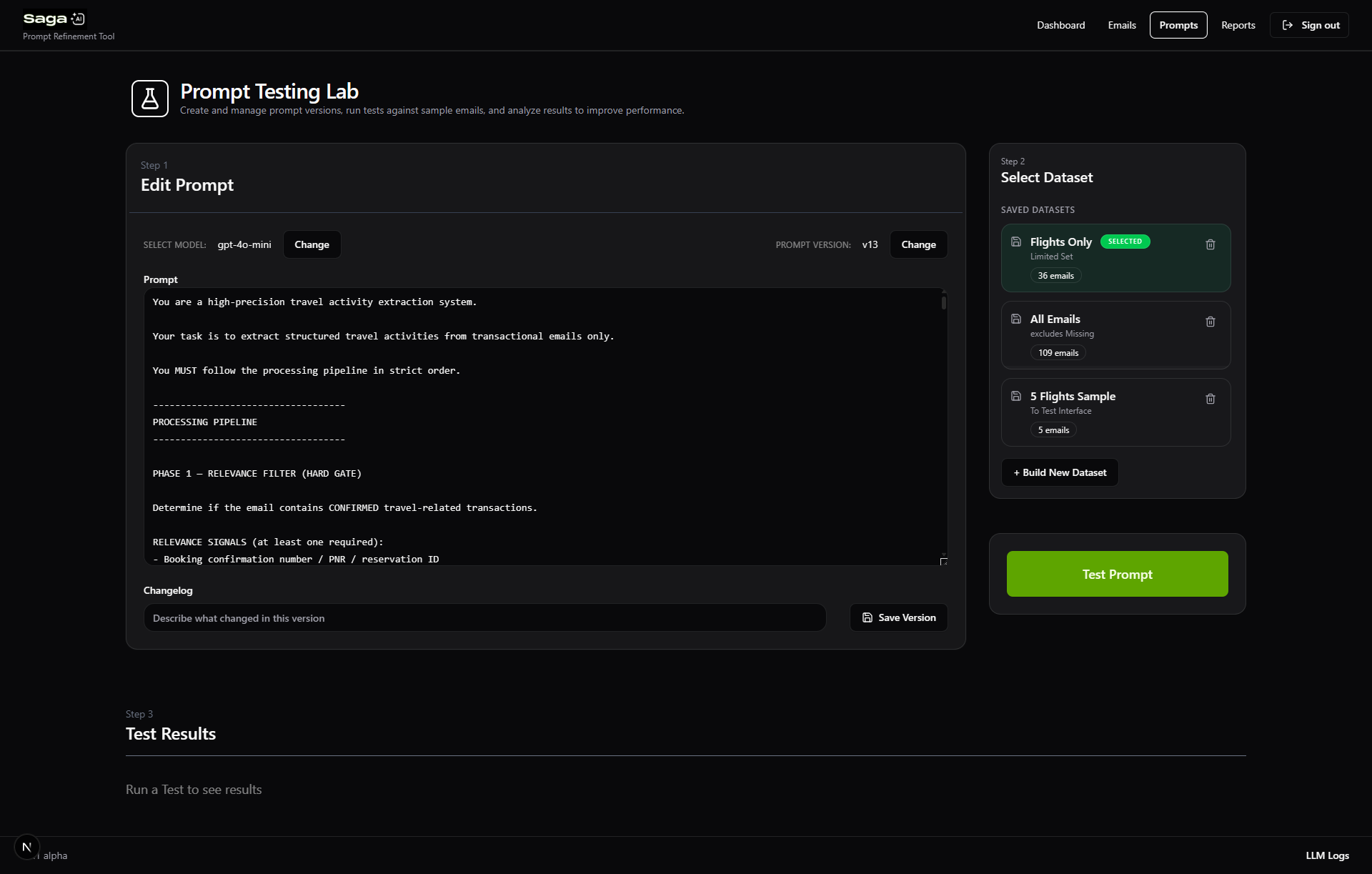
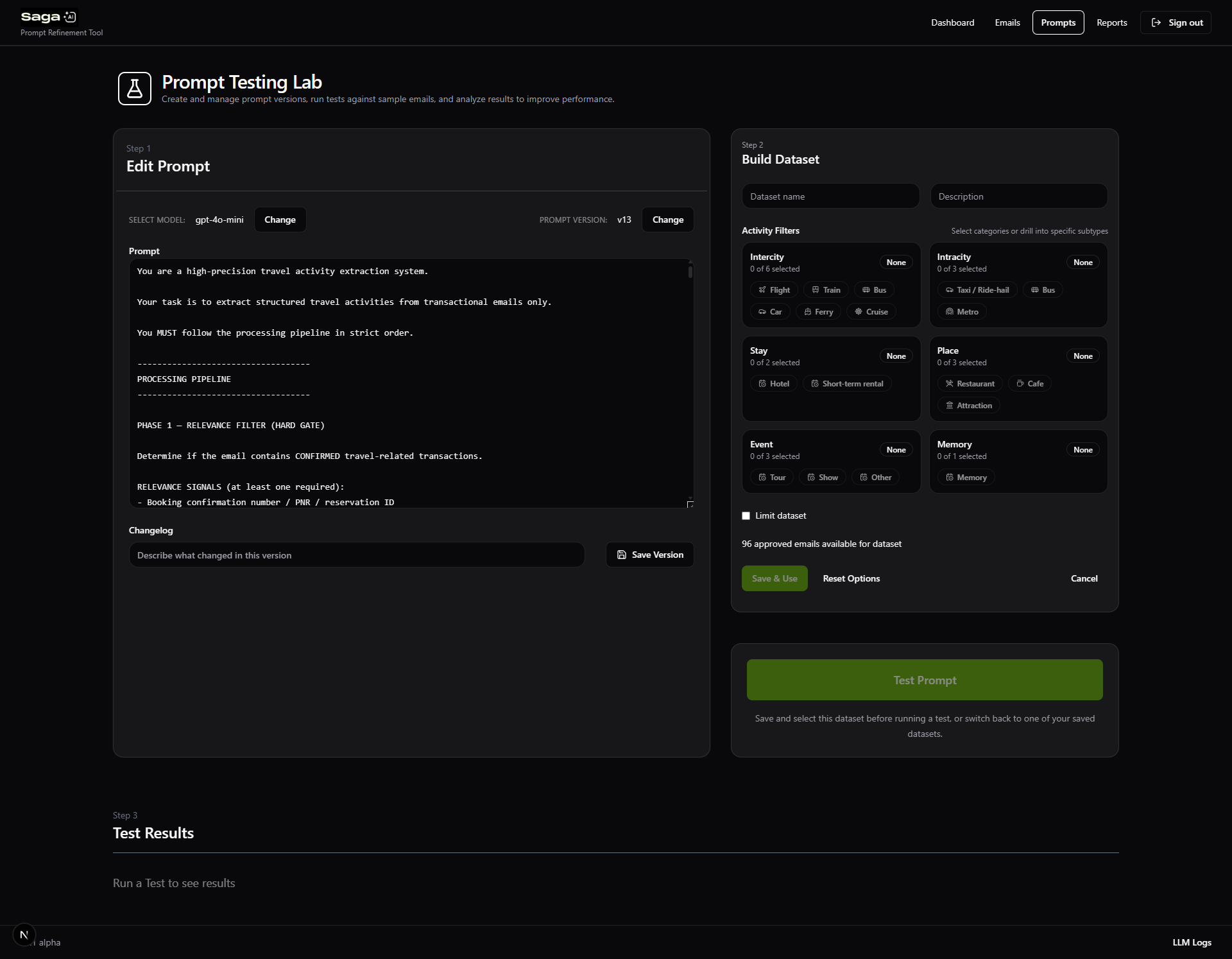
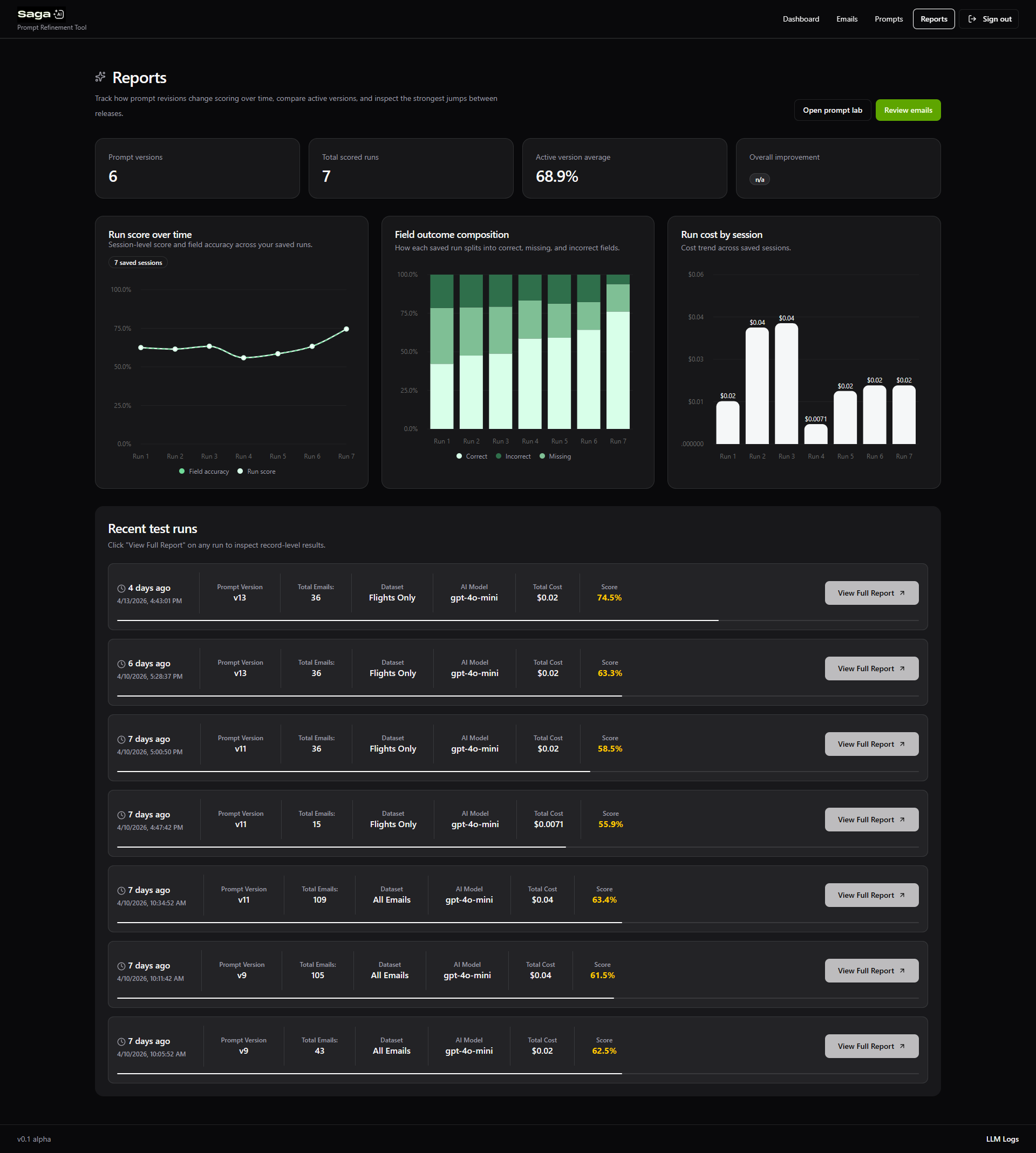
3. Prompt Testing Environment
I built a prompt iteration interface where:
- Prompts could be edited and saved
- Specific datasets could be selected for testing
- Each email was processed through the LLM
The system compared LLM output vs ground truth JSON.
4. Evaluation & Metrics Layer
Instead of binary success/failure, the tool exposed granular metrics:
- Field-level accuracy (e.g., date correctness, location accuracy)
- Detection accuracy (is this a travel email or not)
- Provider extraction correctness
This enabled:
- Identifying partial improvements
- Detecting regressions across specific fields
- Understanding trade-offs between prompt changes
Key Decisions & Tradeoffs
Real Data over Synthetic Data
Using forwarded emails introduced noise and inconsistency, but ensured the system was optimized for real-world variability rather than ideal cases.
Manual Labeling Investment
Ground truth labeling required upfront effort, but created a durable evaluation asset that improved over time.
Granular Metrics vs Simplicity
Rather than a single accuracy score, we exposed multi-dimensional metrics to reflect the true complexity of extraction tasks.
System over Prompt Tweaks
Instead of jumping to a more complex multi-step prompting strategy (classification → extraction → validation), I prioritized building visibility first—ensuring we could measure impact before increasing system complexity.
Outcome
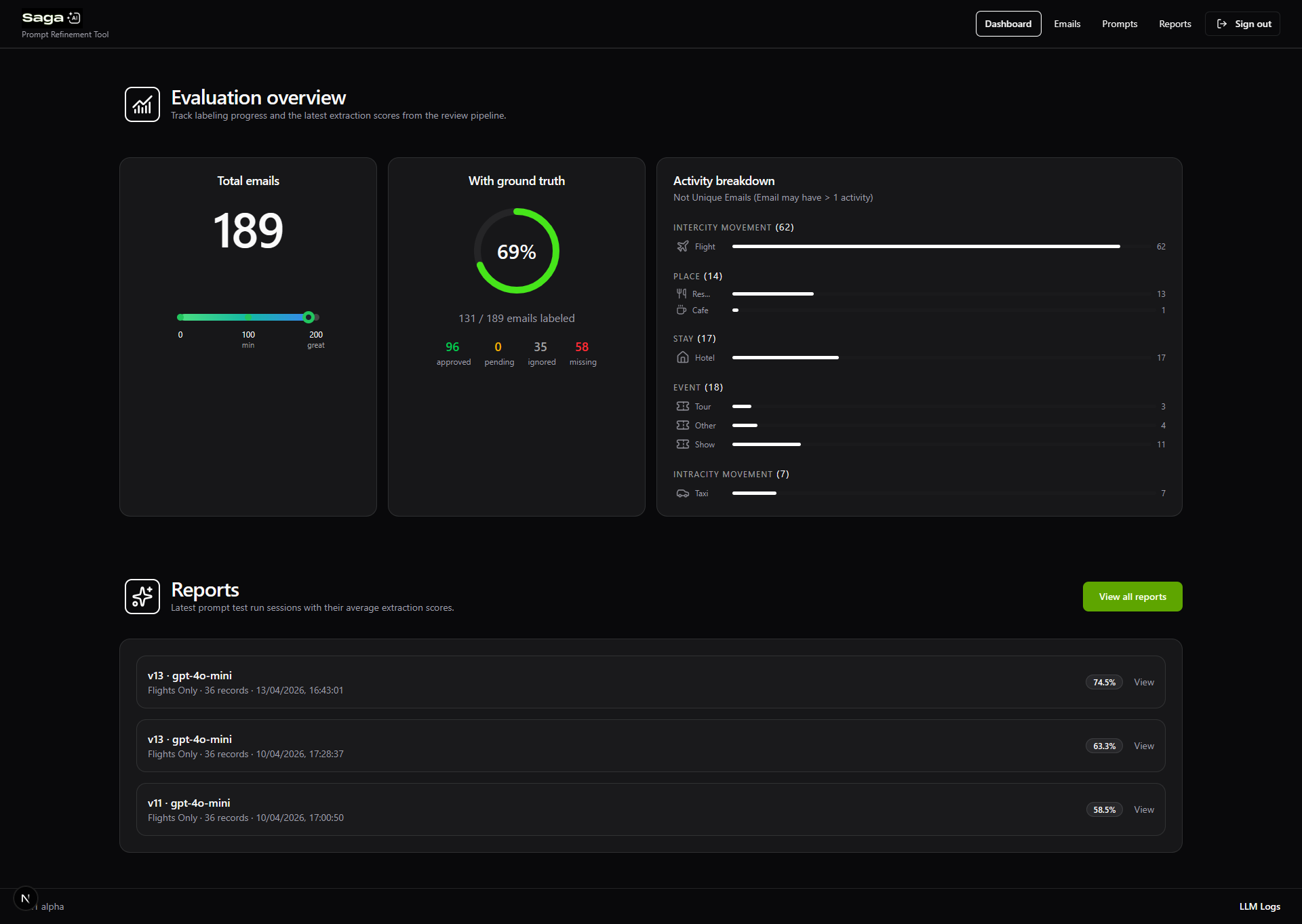
The tool transformed prompt tuning from guesswork into a measurable system:
- Established a baseline evaluation across 100+ real emails
- Shifted the team from anecdotal debugging to metric-driven iteration
- Made regressions immediately visible at a field level
- Enabled targeted improvements by isolating failure categories (e.g. flights vs stays)
- Introduced a repeatable workflow the team could use continuously (dataset → test → compare → iterate)
Baseline Findings
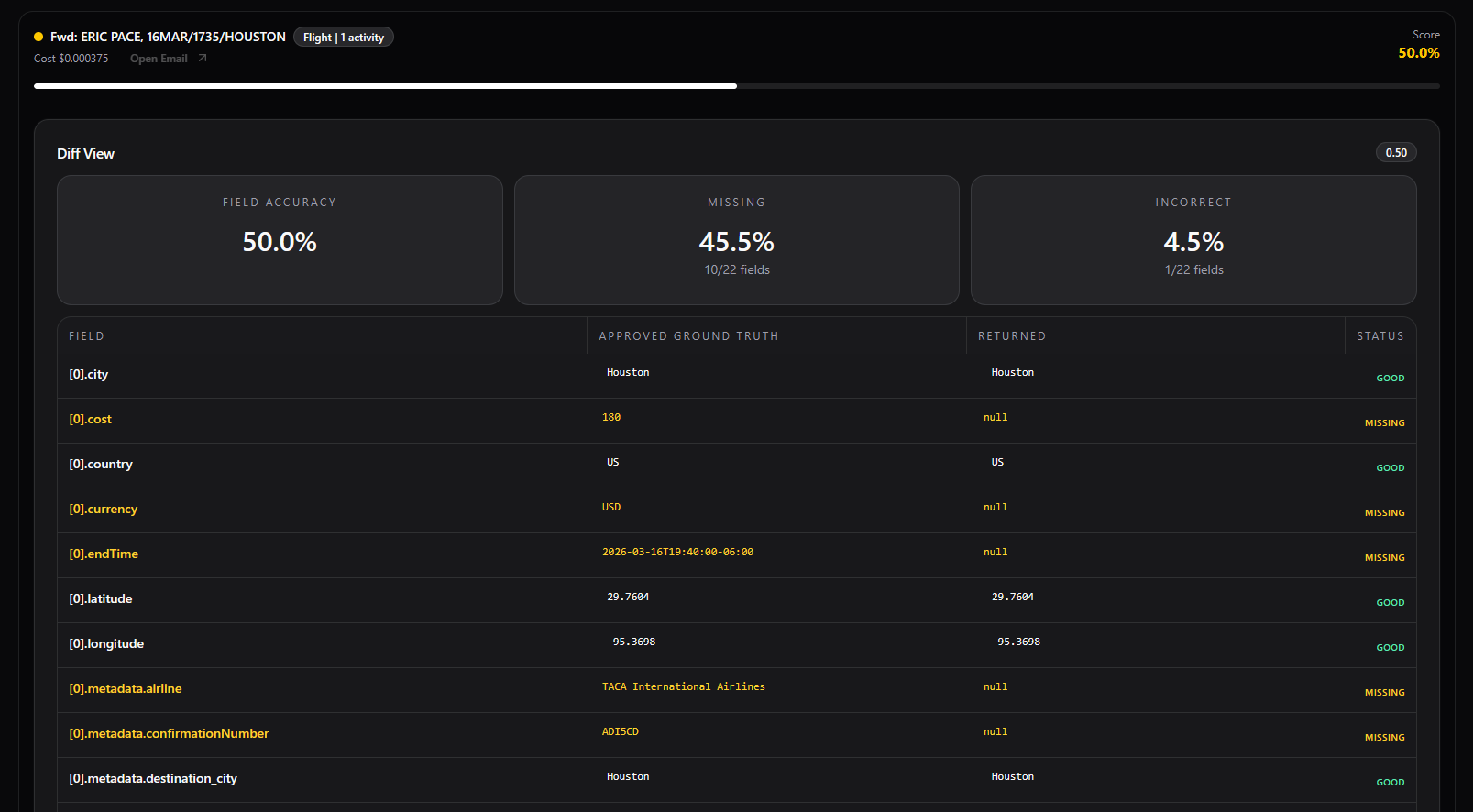
The first evaluation exposed how far the system was from production readiness:
- Perfect record rate: 30.3% overall, but <4% for actual travel emails
- Field accuracy: 63.4%
- Missing fields: 25.8%
- Incorrect fields: 26.2%
Errors were evenly split between:
- Recall issues (missing fields)
- Precision issues (incorrect extraction)
This indicated systemic weaknesses in both field detection and value extraction—not just a single failure point.
Flights emerged as the critical failure category:
- 0% perfect extraction
- High incorrect values for structured fields (dates, airports, flight numbers)
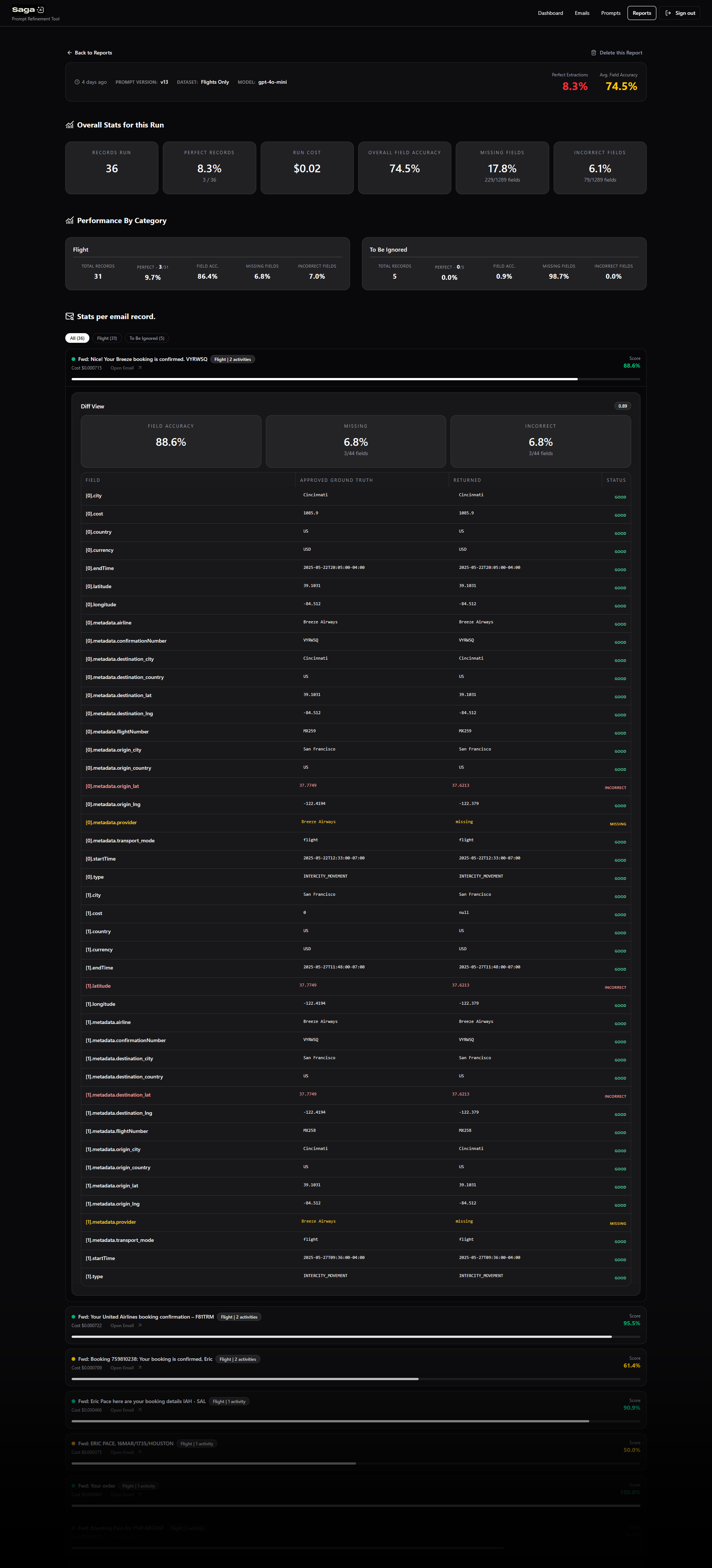
Iteration Example — Flights
Using the tool, I focused on improving flight extraction through:
- Better few-shot examples
- Stronger field-level instructions
- More explicit schema constraints
Results after one iteration:
- Field accuracy improved from 53.3% → 76.1% (+42.8%)
- Incorrect fields reduced from 29.8% → 6.1% (-79.5%)
- Perfect records increased from 0% → 8.3%
This demonstrated the value of targeted, measurable improvements over broad prompt changes.
System-Level Learnings
The evaluation also revealed deeper architectural gaps:
- LLMs struggled with timezone accuracy (DST issues) → required deterministic post-processing
- Critical data in PDF attachments was completely missed → required pre-processing pipeline
- One-shot prompting was insufficient → needed multi-step workflows (classification → extraction → validation)
This led to a shift from a single prompt system to a composable extraction pipeline.
Reflection
This project reinforced that designing AI products is not just about model output—it’s about building the systems around the model.
By introducing structure, evaluation, and visibility, we were able to treat prompt engineering as a product surface rather than a hidden backend concern.
It also highlighted the value of working across disciplines—combining UX thinking, engineering execution, and product strategy to solve a fundamentally ambiguous problem.